How to extract/scrape the main content of a webpage while crawling. A function that allows you to customize which tags to include/exclude.
crawling
scraping
advertools
xpath
Author
Elias Dabbas
Published
June 26, 2024
Modified
July 12, 2025
How to extract body text content from a webpage
Usually when crawling we are interested in extracting and analyzin the main content of a webapage. Whether this is a blog post, news article, product description, or an opinion piece, we want to get that text without the boilerplate (navigation, footers, etc.).
This is a flexible function that generates that XPath selector, and it can be modified easily. The main idea is based on the fact that some HTML tags are primarily used to display text (h1, h2, span, bold, etc), and others that aren’t (script, img, video).
Text tags
You can easily change which tags you want to consider as text tags and which you don’t, depending on your the particular website you are crawling.
Non-text tags
In some cases there are tags that might contain text that you might be interested in. For example iframes, which might include interesting content in some cases. Using “text” to differentiate between the two categories of tags might not be ideal in some cases. Usually nav elements contain text and links, but not as part of the main content of a page.
In any case you can modify the elements you want and get the final XPath expression.
Table data
Tables can have a lot of valuable information related to the page, but sometimes, they contain a lot of numbers that don’t really add any value to the content. For this reason, the include_tables parameter can be used to determine whether or not you want table tags to be included bodytext_xpath(include_tables=False). Again, you can manually set any tags you want to include or exclude and fully customize the output string.
def bodytext_xpath( include_tags=("a","abbr","address","article","b","bdi","bdo","blockquote","caption","cite","code","data","dd","del","details","dfn","div","dl","dt","em","figure","figcaption","h1","h2","h3","h4","h5","h6","i","ins","kbd","li","main","mark","menu","ol","p","pre","q","rp","rt","ruby","s","samp","section","small","span","strong","sub","summary","sup","table","tbody","td","th","thead","tr","time","u","ul","var", ), exclude_tags=("area","aside","audio","base","button","br","canvas","col","colgroup","datalist","embed","fieldset","footer","form","head","header","iframe","img","input","label","legend","link","map","meta","nav","noscript","object","optgroup","option","output","param","picture","script","search","select","source","style","svg","textarea","tfoot","title","track","video", ), include_tables=True,):"""Create an XPath expression to extract body text from a web page. This approximates the page content that you are probably interested in (article text, product description, blog post, etc.) You can change which tags are included and which are not by modifying the available parameters. Parameters ---------- include_tags : list A list of tags that typically contain text elements. You can add to it (if you want to include text in iframes, or td for example.) exclude_tags : list A list of tags that typically don't contain text (video, image, etc.). Make sure to remove the ones you don't want from this list if you want to modify the first one. include_tables : bool Whether or not to include data from tables in the HTML page. Returns ------- xpath_selector : str An XPath selector to be used in scraping the main body text of a webpage. """ table_tags = ["table","caption","colgroup","col","thead","tbody","tfoot","tr","th","td", ] include_tags =sorted(set(t.lower() for t in include_tags)) exclude_tags =sorted(set(t.lower() for t in exclude_tags)) common_elements =set(include_tags).intersection(exclude_tags)if common_elements:raiseValueError(f"Please make sure you don't include and exclude the same elements:{common_elements}" )ifnot include_tables: include_tags =sorted(set(include_tags).difference(table_tags)) exclude_tags =sorted(exclude_tags + ["table"]) include_tags_expr =" or ".join(f"self::{tag}"for tag in include_tags) exclude_tags_expr =" and ".join(f"not(ancestor::{tag})"for tag in exclude_tags) final_exp =f"//body//*[{include_tags_expr}][{exclude_tags_expr}]/text()"return final_exp
Running this function give us the XPath expression that can be used with any SEO crawler if you want to try it:
bodytext_xpath()'//body//*[self::a or self::abbr or self::address or self::article or self::b or self::bdi or self::bdo or self::blockquote or self::caption or self::cite or self::code or self::data or self::dd or self::del or self::details or self::dfn or self::div or self::dl or self::dt or self::em or self::figcaption or self::figure or self::h1 or self::h2 or self::h3 or self::h4 or self::h5 or self::h6 or self::i or self::ins or self::kbd or self::li or self::main or self::mark or self::menu or self::ol or self::p or self::pre or self::q or self::rp or self::rt or self::ruby or self::s or self::samp or self::section or self::small or self::span or self::strong or self::sub or self::summary or self::sup or self::table or self::tbody or self::td or self::th or self::thead or self::time or self::tr or self::u or self::ul or self::var][not(ancestor::area) and not(ancestor::aside) and not(ancestor::audio) and not(ancestor::base) and not(ancestor::br) and not(ancestor::button) and not(ancestor::canvas) and not(ancestor::col) and not(ancestor::colgroup) and not(ancestor::datalist) and not(ancestor::embed) and not(ancestor::fieldset) and not(ancestor::footer) and not(ancestor::form) and not(ancestor::head) and not(ancestor::header) and not(ancestor::iframe) and not(ancestor::img) and not(ancestor::input) and not(ancestor::label) and not(ancestor::legend) and not(ancestor::link) and not(ancestor::map) and not(ancestor::meta) and not(ancestor::nav) and not(ancestor::noscript) and not(ancestor::object) and not(ancestor::optgroup) and not(ancestor::option) and not(ancestor::output) and not(ancestor::param) and not(ancestor::picture) and not(ancestor::script) and not(ancestor::search) and not(ancestor::select) and not(ancestor::source) and not(ancestor::style) and not(ancestor::svg) and not(ancestor::textarea) and not(ancestor::tfoot) and not(ancestor::title) and not(ancestor::track) and not(ancestor::video)]/text()'
Examples
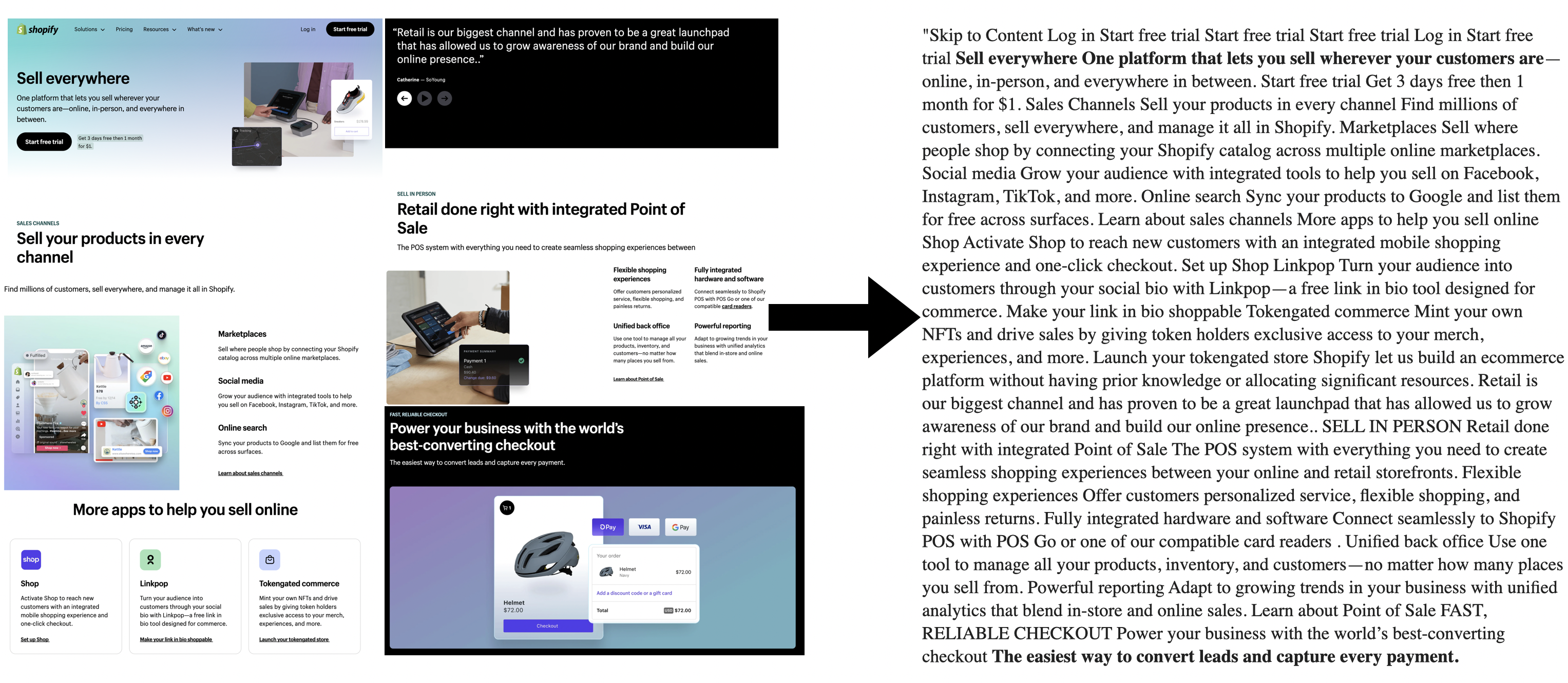
In this example you can see that the extracted text starts with “Select Page”, which is hidden. Then you can see “From Merchant Feed…”, right after the navigation links. The extracted text ends with “using WordLift”, and the remaining text is not extracted because it is part of the footer.
Here, there is a longer hidden text, “Skip to content…free trial”, then we start with the main content, “Sell everywhere…”, until “capture every payment”.